畅销榜TOP 1新游如何让玩家沉迷?制作组:让AI先玩10亿次
畅销榜TOP 1新游如何让玩家沉迷?制作组:让AI先玩10亿次

在今年日本CEDEC开发者大会上,《学园偶像大师》(后简称学马仕)开发商QualiArts。以及QualiArts母公司CyberAgent,共同分享了他们对于AI技术在游戏平衡性优化方向上的应用实例。
在上一篇分享中,我们聊到学马仕的3D技术和细节打磨,如果说3D技术并非适用所有游戏,那么今天要聊的AI技术则更具备普适性。
学马仕的玩法比较独特,它的系统框架是类似《赛马娘》的养成模式,但在具体的每个养成环节中,学马仕又加入了名为训练课程,实为卡牌构筑(DBG)的模式。

DBG玩法的魔性,自《杀戮尖塔》走红以后就为人熟知,学马仕的微创新玩法,自然也让粉丝和玩家为之着迷。当然,从开发的角度来看,作为一款需要长期更新的网游,势必要在基础的DBG过程中不断加入新卡,那么卡牌的平衡性调整就会面临快速增长且长期的压力。
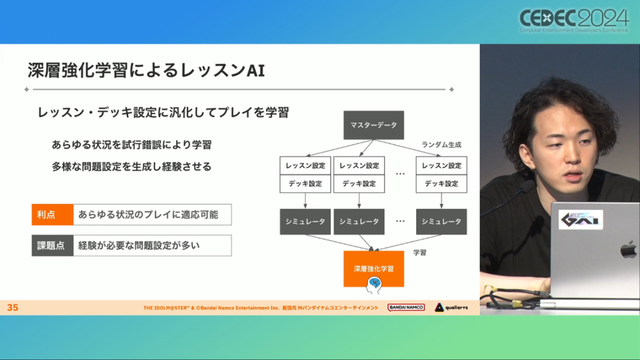
所以学马仕项目组借助深层强化学习开发了两套卡牌游戏AI,以及一套平衡性调整支持系统,来解决游戏加入新卡牌后的平衡问题。
左:CyberAgent 游戏和娱乐部门AI战略总部研究工程师伊原滉也;右:QualiArts那須勇弥。
具体来说「平衡性调整的难点」。
学马仕里玩家需要先构筑卡组,在养成环节的课程玩法中,从牌山里抽取手牌并打出,同时卡牌产生的效果也会随情况而变化。
因此根据卡牌组合情况的不同,即使卡组里存在所谓破坏平衡的卡牌,开发组也很难通过人力准确地找到它。

制作组的应对方法,一是用灰盒最佳化技术,生成能够在庞大的组合当中寻找最强卡组的「卡组探索AI」,二是用深层强化学习技术,生成可以尝试各种对局的「课程AI」。两者协同之下,就能解决对应问题。

由于学马仕要考虑到长线运营,所以短期内增加的新卡牌也是一种挑战。毕竟,每个月都要实装新卡的工作流程里面,如果AI的学习时间在10天以上,那么平衡性调整之后连验证时间都留不下来。
所以,制作组对指定学习模型,尝试了一种将追加数据进行转移学习的方法。这种方法的效率远比重复「从头开始学习」的效率更高,把超过10天的学习过程,缩减到10个小时的水准。同时催生了「允许策划方完成模拟的平衡调整支持系统」。

其中,QualiArts负责开发游戏内逻辑,并为平衡调整支持系统构建Web应用程序/基础设施,而CyberAgent负责开发卡组探索AI和课程AI。
 01 什么是平衡调整支持系统?
01 什么是平衡调整支持系统? 如上所述,可成AI仅在第一次生成的时候使用从头学习创建的模型,然后会在添加主数据时执行迁移学习。这之后,AI会围绕新追加的卡牌构筑牌组,并于反复模拟和确认结果之后,如果没有问题就正式上线实装新卡。

关于从头学习和迁移学习,游戏大致可以按照角色属性「意义」和「逻辑」分开进行。
如下图的这些控制台管理元数据,实际模型保存在 WB(开发人员协作平台)中。无需输入参数,这是机器学习的典型特点,即使没有配套知识也很容易使用。

学习执行的核心逻辑在Unity存储库中实现,并且设计和实装也可以兼容在.NET运行时上的运行。于是,通过Python实装的课程AI,就可以通过socket通信来进行播放(学习)。

以这种方式管理人工智能模型和执行学习的问题在于,开发者很难理解模型学到了什么,也很难理解模型本身的强度(即可靠性)。

解决前一个问题,需要显示学习前新学习目标的技能卡和物品的效果差异。解决后一个问题,通过与「能确切产生较高分数的方法(MCTS)」进行比较来实现。
顺便一提,所有学马仕的卡牌效果说明,都是根据相关主数据自动生成的,因此可以动态检测其差异。

在工作流程中的「卡组探索」功能,采用了以 Google Cloud 的 Cloud Run/Batch 为中心的无服务器架构。

这个架构能实现并行执行,并允许在需要的时候灵活地进行重新缩放。

此外,卡组信息和课程AI的游玩日志都会被储存下来,并可以使用电子表格数据连接器进行同步。这使得游戏策划可以使用他们习惯的电子表格来随意处理和分析数据。

通过以上技术,项目组实现了以下结果:
通过在游戏上线前运行上述系统,可以在上架前模拟超过1亿套卡组,累计课程训练次数超过10亿次。如果用真人来尝试做到这个结果,即使每次可成只算一分钟,也需要大约1900年才能搞定。
通过这么多次的模拟,制作组也能够发现在设计或测试游戏时没有注意到的细节,从而对平衡性调整产生很大的帮助。
具体的例子包括「防止顶级玩家的牌组变得相似」和「防止技能卡组合出现循环」。此外,一个衍生的好处,是这套技术也能帮忙检测游戏BUG。
 02 「课程AI」的训练
02 「课程AI」的训练 项目组对于「课程AI」的要求如下:
1.任何情况下都可以打出任何牌;
2.每次游玩的时间小于0.1秒;
3.从添加新卡到确认结果的时间在36小时以下。
换句话说,AI需要以最高效率、最快速度为目标,在更改主数据后36小时内进行学习,并生成易于理解的模拟结果。

学马仕的课程玩法,可以看做马尔可夫决策过程(MDP)来进行建模。这个模型会根据当前的「状态」和「行动」,精确得出下一个「状态」。
将上述模型与蒙特卡罗树方法(MCTS)的博弈树搜索方法相结合,我们可以不断接近更精确的最优行为。顺便一提,其背后的原理与计算机读取将棋或围棋的走法相同。


但上述方法的问题是计算时间较长,执行一个包含9个回合的课程,平均消耗的时间为1416.2秒。
作为解决方案,制作组采用了一种旨在使用「深度强化学习」来近似最佳游戏行为的方案。简而言之,就是让人工智能体验各种情况并通过反复试验来学习。
结果来看,制作组得到的AI,可以打出与 MCTS 相当的分数,并且打一局牌的时间可以控制在0.1秒以内。如下图,虽然平均成绩稍低,但平均单局时长符合0.1秒的要求,相当于相同时间内,可以利用AI进行14000倍以上的对局测试。

此外,在不断添加新卡的运营情况下,制作组必须解决课程AI的学习时间问题。这是因为,要达到上述性能水平,AI需要对局至少3亿次,相当于耗时300小时。

然而,随着新卡数量的不断增加。这种机制将达到上限,因此制作组使用大规模语言模型(LLM,据说使用了 OpenAI 的 Embeddings API)中的文本嵌入来表达状态。
通过使用卡牌效果文本而不是游戏内的结构数据,该系统可以无视产品画面样式的变化,并且具有无需额外学习即可引入新卡牌的优点。

结果来看,前文提到的迁移学习能在更短的时间内完成,相比在相同时间内使用从头学习的模式,也能获得更精确的对局过程。

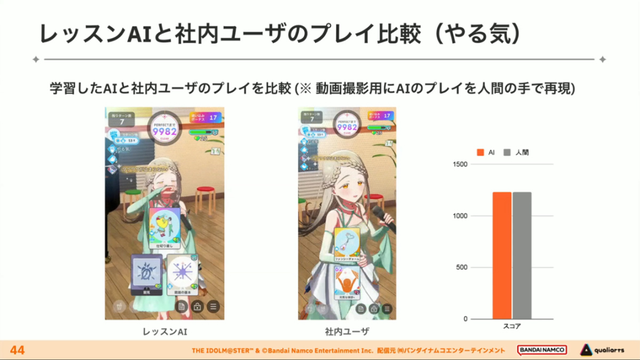
经过上述方式训练出来的课程AI,玩起游戏来已经与不逊色于人类,甚至与人类十分接近了。
即使与制作组内熟悉学马仕的成员相比,课程AI有时在分数上还能胜过这些玩家,而且哪怕打法上的差别虽然只是一招,带来的差距也十分明显。

 03 卡组构筑AI对LLM的应用
03 卡组构筑AI对LLM的应用 开发「卡组构筑AI」的目的,是为了发现可以破坏游戏平衡的得分最高的卡组。制作组认为,当AI打出极端高分的时候,往往会关联到太强的卡牌或卡组。

哪怕按照游戏刚上线时的卡牌和道具来算,其组合数也十分庞大(超过10的20次方),并且每次更新时都重新计算和排查一遍的做法也很不切实际。

因此,制作组没有使用暴力解决问题的「黑盒优化」技术,而是采用了与问题部分关联的「灰盒优化」技术。此外,这里还采用了使用LLM的文本嵌入技术。


卡组探索算法采用了遗传算法。这个算法机制,会将两个卡组组合起来生成子代卡组,而后评估高分解法,再将优秀解法继续组合生成下一代,并在其中通过引起突发变化来寻找(近似)最佳解。


该算法一般用作黑盒优化的框架,但这次通过引入LLM向量化的卡牌信息,实现为灰盒优化算法。
具体来说,是在卡组集合中构建函数分布,并从高斯分布中进行点的采样,再根据有空位的点附近寻找卡牌,而后将卡牌加入卡组。如果方差大,则生成结果接近随机选择,如果方差小,则生成结果是亲代子代卡组相近。


以上尝试的结果如下:
让一个经过迁移学习的AI执行卡组探索时,设定卡组总数为20~30张牌、玩家初始卡组数量为6~8张牌、课程进行12轮。能看到,相比完全随机采样算法,生成的结果效率提高了约15%。

通过使用这些平衡调整支持系统,学马仕自服务开始以来,已经模拟了超过1亿套卡组和10亿次课程。给项目组带来的好处,是调整和优化了很多人力无法顾及的卡组和流派。

如今,绝大多数游戏对AI的应用还是停留在AIGC生成资源的方面,而我们从学马仕的案例来看,AI对于游戏优化测试、平衡性调整,也有不小的帮助。
且不论此前业内「AI将淘汰99%从业者」的论断,至少当下来看,掌握更多的AI技术,确实也能帮我们提高研发效率,优化游戏素质。
相关阅读
-
 畅销Top 5:这家大厂的怪招,不只茅台和马喽
畅销Top 5:这家大厂的怪招,不只茅台和马喽最近《三国志·战略版》(以下简称三战)又回到畅销榜Top5了。 如果要说过去五年里,国内市场最赚钱的游戏有哪些,那累计赚了数百亿,凭一己之力让灵犀互娱站起来的三战,势必榜上有名。...
-
 小游戏畅销榜放置卡牌品类的机会如何以大王不好啦的爆款案例分析
小游戏畅销榜放置卡牌品类的机会如何以大王不好啦的爆款案例分析文/ET得益于《咸鱼之王》《次神光之觉醒》等游戏的优异市场表现,放置类、卡牌类游戏在微信小游戏中愈发热门。其中《几何王国》从今年春节开始一直维持在畅销榜头部,最高排名一度进入Top...
-
 畅销Top 4,网易一个关键决策,拯救了差点被遗忘的神作
畅销Top 4,网易一个关键决策,拯救了差点被遗忘的神作《炉石传说》又火了,还一度冲上游戏畅销榜Top 4?不是哥们儿,今夕是何年? 自9月25日《炉石传说》国服回归后,恐怕不少人都有这样的想法。 它能火,倒是没多少人意外。小别胜新...
-
 Steam一周销量Top 10:《龙珠电光炸裂》榜首将延期上线
Steam一周销量Top 10:《龙珠电光炸裂》榜首将延期上线本周Steam平台的畅销游戏榜单已经出炉,其中,《龙珠电光炸裂!ZERO》高居榜首。该游戏尚未正式发售,目前仅提供豪华版抢先体验。根据榜单显示,《龙珠电光炸裂!ZERO》以显著优势...
-
 轻投流的潜力小游戏,自走棋对战玩法的世界守卫军如何逆势生长?
轻投流的潜力小游戏,自走棋对战玩法的世界守卫军如何逆势生长?文/ET《世界守卫军》在今年4月份首次上架微信小游戏后,在7月份一度进入微信小游戏畅销榜Top30。但游戏整体排名的波动较大,10月初几乎掉出畅销榜,没想到近期又重新杀回畅销榜19...
-
 红月战神官网:红月战神职业玩法深度解析,助你快速上手!
红月战神官网:红月战神职业玩法深度解析,助你快速上手!作为一款令人难忘的经典怀旧手游,《红月战神》散发着独特而迷人的魅力。首先,其呈现出的精美画面和流畅操作体验令人称赞,能让玩家全身心地沉浸于游戏世界之中;其次,丰富多元的玩法更是让人...
-
 莉莉丝新作公测:今日登顶免费榜,曾跻身多国畅销榜Top 10
莉莉丝新作公测:今日登顶免费榜,曾跻身多国畅销榜Top 10由乐狗研发,莉莉丝发行的《万龙觉醒》在今天公测后,便登顶iOS游戏免费榜。 2023年3月,该作在海外市场上线。此后不久,便在近100个国家地区的App Store中冲进了免费榜...
-
 月流水过亿后,他们把一座山搬进了游戏
月流水过亿后,他们把一座山搬进了游戏或许,我们又该刷新对小游戏的刻板印象了。 最近,葡萄君发现至今仍霸榜微信畅销榜TOP 3、预估月流水过亿的《寻道大千》,更新了与黄山旅游联动的新版本,相关内容在B站、小红书等平台...
大家都在看
-
 看照片都能看醉!《如龙8外传:夏威夷海盗》拍照模式曝光
看照片都能看醉!《如龙8外传:夏威夷海盗》拍照模式曝光如龙工作室近日展示了其新作《如龙8外传:夏威夷海盗》的拍照模式。在游戏内的拍照模式中,主角真岛吾朗(60岁)手握手机,展开了一场滑稽的自拍活动。不仅如此,游戏中还配备了美颜功能,使...
-
 传奇世界:当年44区最狂道士,PK没对手?连火星战神也打不过
传奇世界:当年44区最狂道士,PK没对手?连火星战神也打不过各位爱好传奇世界的老玩家们,今天给大家带来一个令人热血沸腾的传奇故事!说起传奇世界第一道士,不少人都会想到1区开天的火星战神。这位从菜鸟到神话的传奇人物。可你们知道吗?在44区有一...
-
 女娲终于迎来变异!程咬金喜忧参半,对抗貂蝉要退役了吗?
女娲终于迎来变异!程咬金喜忧参半,对抗貂蝉要退役了吗?11.15正式服更新,对貂蝉、程咬金进行了平衡性调整。同时,新版女娲也一并上线,下面我们就来分析下他们调整后的强度如何!【女娲】我们先来看下女娲,她的技能调整后上限很高,大约分为5...
-
 三国杀:高嘲讽低强度,设计师脑子有问题?
三国杀:高嘲讽低强度,设计师脑子有问题?游戏里面有一些武将嘲讽度特别的高,只要我们选择出来之后,就有可能会遭受到对方的针对。一般这样的武将,都能够给敌人造成特别大的威胁,必须要优先解决才能以除后患。可是有些武将,他们嘲讽...
-
 再次暴雷的尘白禁区,还是没意识到二游文案的重要性
再次暴雷的尘白禁区,还是没意识到二游文案的重要性好家伙,今年真不愧是二游吃瓜吃到撑的一年啊!最近尘白禁区的2.3新版本引发了大规模文案暴雷的瓜相信各位已经都吃到了,简单来说,就是有玩家发现新版本的文案中,存在着大量的不合适的描写...
-
 DNF:嘉年华集卡活动来了!欧皇可拿红11券,保底可得153天黑钻
DNF:嘉年华集卡活动来了!欧皇可拿红11券,保底可得153天黑钻在11.21嘉年华版本上线之后,一个叫作史诗之路集卡赢好礼的活动,也是上线了!该活动可通过抽卡、集卡,兑换的方式来获得奖励。那么活动怎么玩?奖励又怎么样呢?嘉年华集卡活动来了首先,...
-
 DNF手游:体验服史诗辅助装备已上线拍卖行,价格能否超过骨戒?
DNF手游:体验服史诗辅助装备已上线拍卖行,价格能否超过骨戒?DNF手游独创可交易史诗辅助装备马上就要上线了,从体验服目前的情况来看,价格可以媲美骨戒,基本上平均价格处于150W,保底75W泰拉。01正式服与体验服之间拍卖价格参考基准左侧为正...
-
 三国杀:王濬楼船下益州,灭霸终于获得了该有的强度,太感动!
三国杀:王濬楼船下益州,灭霸终于获得了该有的强度,太感动!大家好,这里是你们的老朋友手杀菌!“王濬楼船下益州,金陵王气黯然收”。作为与杜预同时期的强力猛将,在三国杀中却有着完全不符合自身设定的强度,像杜预的强度非常高,而灭霸只能作为一个搞...
-
 周瑜是战士,守约是刺客,蔡文姬是法师,强行加副职业有必要吗?
周瑜是战士,守约是刺客,蔡文姬是法师,强行加副职业有必要吗?大家好我是指尖,王者中的大多数英雄都是有两个标签的。主职业和副职业,如赵云,是战士,也是刺客,但有些英雄只有一个标签,像沈梦溪,就只是单纯的法师,但不知道策划出于怎样的考虑,有些英...
-
 腾讯高层评价《黑神话:悟空》 玩家:没玩过的快去试试
腾讯高层评价《黑神话:悟空》 玩家:没玩过的快去试试腾讯最近公布了其2021年第三季度的财务报告。报告显示,该公司在该季度实现了1,671.9亿元人民币的营收,同比增长8%。其中,游戏业务的增长主要得益于《DNF手游》和《三角洲行动...
- BGM全程碾压OP!网友:BGM距离晋级只需一场比赛!
- Mlxg疯狂爆喷无状态:打团少人怎么打?带个人机中路怎么赢
- 三核体系发力,Uzi薇恩难挽狂澜,BYG击败GM,晋级淘汰赛
- Uzi:谢幕战给你们来把EZ璐璐,BO5的最后一场
- Uzi:我们这没人敢迟到,昨天Gogoing顶着38度打比赛
- 多兰开播谈加盟T1过程太魔幻,见到Faker得到回应乐开花
- [传奇杯S2]【Puff队 vs 姿态队】全场速看
- [传奇杯S2]【Icon队 vs Doinb队】全场速看
- [传奇杯S2]【Letme队 vs Leyan队】全场速看
- [传奇杯S2]【宝蓝队 vs Ning队】全场速看
- 众人看IG全神班,杰杰确定搭档仁川中上,还有GALA加入
- 严君泽谈IG新赛季阵容:这个队伍一般人教不了吧
- BYG突然发力赢下M3,距离晋级只差一场!
小编推荐
-
 魔兽世界怀旧服:20周年服和哈霍兰服开吵,一定要分成两个派别吗 2024-11-16 13:05:53
魔兽世界怀旧服:20周年服和哈霍兰服开吵,一定要分成两个派别吗 2024-11-16 13:05:53 -
梦幻西游:道人下线后产出的超兽诀变少了,是故意降低了几率吗? 2024-11-16 20:13:57
-
DNF手游:红眼能用杀猪刀了?全职业武器平衡曝光,火巨更胜一筹 2024-11-17 18:40:16
-
武侠游戏哪个好 热门武侠游戏盘点 2024-11-18 18:44:40
-
新能源浪潮中,上汽大众的“大众心脏”如何坚守荣耀? 2024-11-21 20:12:56
-
《魔兽世界》Plus服:P6无尽诺格弗格药剂的获取方法 2024-11-21 14:59:09
-
梦幻西游:胆大的赚的更多,把区里的高否定都买了,涨价十倍上CBG 2024-11-20 13:45:01
-
《魔兽世界》Plus服:P6安其拉幻化武器模型被发现 2024-11-18 14:27:57
-
梦幻西游:难怪1星抓鬼这么贵,一组175的五开一轮奖励43W梦幻币 2024-11-18 17:04:34
-
《DNF手游》27号更新前必须要做的3件事,否则囤300疲劳也到不了60级,白白浪费2000碳 2024-11-19 12:07:37